廣州歐米諾國(guó)際餐飲管理有限責(zé)任公司 引領(lǐng)餐飲管理新風(fēng)尚

在競(jìng)爭(zhēng)激烈的餐飲市場(chǎng)中,廣州歐米諾國(guó)際餐飲管理有限責(zé)任公司以其前瞻性的戰(zhàn)略思維和卓越的管理能力,逐漸成為行業(yè)的標(biāo)桿。公司專注于為餐飲品牌提供全方位的管理解決方案,從品牌孵化、運(yùn)營(yíng)優(yōu)化到市場(chǎng)拓展,歐米諾以其專業(yè)和創(chuàng)新的服務(wù),幫助眾多餐飲企業(yè)實(shí)現(xiàn)高效增長(zhǎng)與可持續(xù)發(fā)展。
作為一家國(guó)際化的餐飲管理公司,歐米諾不僅整合了國(guó)內(nèi)外先進(jìn)的餐飲理念和技術(shù),還結(jié)合本土市場(chǎng)需求,打造出獨(dú)特的服務(wù)體系。公司團(tuán)隊(duì)由資深餐飲專家、市場(chǎng)營(yíng)銷精英和運(yùn)營(yíng)管理人才組成,致力于為合作伙伴提供定制化的策略支持。無(wú)論是初創(chuàng)品牌還是成熟連鎖企業(yè),歐米諾都能通過(guò)精細(xì)化管理和數(shù)據(jù)分析,幫助客戶提升運(yùn)營(yíng)效率、優(yōu)化成本結(jié)構(gòu),并在激烈的市場(chǎng)競(jìng)爭(zhēng)中脫穎而出。
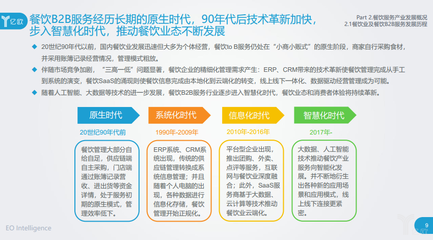
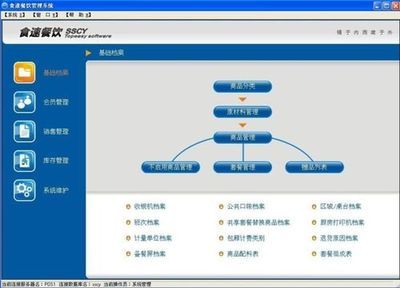
歐米諾的核心優(yōu)勢(shì)在于其系統(tǒng)化的管理方法。公司開(kāi)發(fā)了一套完整的餐飲管理系統(tǒng),涵蓋供應(yīng)鏈管理、人員培訓(xùn)、品質(zhì)控制和顧客體驗(yàn)等多個(gè)環(huán)節(jié)。通過(guò)數(shù)字化工具和智能化解決方案,歐米諾幫助餐飲企業(yè)實(shí)現(xiàn)流程標(biāo)準(zhǔn)化、服務(wù)個(gè)性化,從而增強(qiáng)品牌競(jìng)爭(zhēng)力。公司還注重可持續(xù)發(fā)展,倡導(dǎo)綠色餐飲理念,推動(dòng)環(huán)保實(shí)踐,贏得消費(fèi)者和社會(huì)的廣泛認(rèn)可。
廣州歐米諾國(guó)際餐飲管理有限責(zé)任公司將繼續(xù)深耕餐飲管理領(lǐng)域,拓展國(guó)際合作,引領(lǐng)行業(yè)創(chuàng)新。在消費(fèi)升級(jí)和數(shù)字化轉(zhuǎn)型的浪潮下,歐米諾將憑借其專業(yè)實(shí)力和前瞻視野,助力更多餐飲品牌走向成功,為全球餐飲業(yè)注入新的活力。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.ruidaqh.cn/product/45.html
更新時(shí)間:2026-06-19 05:33:13